「フィルタリング機能の仕組みはどうであれ、とりあえず使ってみたい」という場合はこのページを読み飛ばして、次の「フィルタリング機能の基本設定」をお読み下さり、設定を行って下さい。
●当フィルタで用いている二つの方式について
当プラグインにおけるスパムフィルタリングでは「ブラックリスト参照方式」と「ベイジアンフィルタ方式」を併用しています。
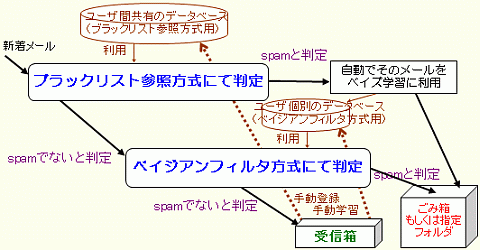
それらの方式の併用に関しては下図のような流れになっています。
すなわち、届いたメールはまず、共有化している「ブラックリスト参照方式」のデータベースに基づいてspam判定を行います。そこでspamと判定された場合にはspamであることを「確定」して、spam用メールフォルダに振り分けると同時に、そのメールをベイジアンフィルタ方式用データベースでの学習に自動利用します(これを自動学習と呼びます)。
共有化している「ブラックリスト参照方式」のデータベースでspamと判定されなかった場合には、ユーザが個別に持っているベイジアンフィルタ方式用のデータベースを用いて、そのメールに対してベイズ理論に基づくspam判定を行います。一定の確率でspamである可能性が高いとされた場合にspamだと「確定」し、やはりspam用メールフォルダに振り分けます。
●二つの方式の比較
| ブラックリスト参照方式 | ベイジアンフィルタ方式 | |
| ユーザの利用方法 | spam登録 | spam学習 |
| 利用するもの | IPアドレス | メール内容(ヘッダ含む)に出現する単語 |
| 利用結果 | ユーザ間で共有化するデータベースに反映 | ユーザ個々で利用するデータベースのみに反映 |
| 当プラグインで対象とするメール | メール言語に関係なし | 日本語、英語 |
| 一般的な関係キーワード | DNSBL、ORBS、サーバのブラックリスト、オープンリレー(Open Relay)、オープンプロキシー(Open Proxy) | ベイズ理論、ベイジアンフィルタ |
●ベイジアンフィルタで使用している二つの指標
ベイジアンフィルタでは「spamらしさ」と「真っ当なメールらしさ」の二つを利用して、新しく届いたメールの「spamである確率」を出して判断しています。「spamらしさ」も「真っ当なメールらしさ」も、それぞれ、それまでに蓄積された「spam」と「真っ当なメール」から学習した結果に基づきます。
この時、spamから「spamらしさ」のデータベースを構築することを「spam学習」、「真っ当なメール」から「真っ当なメールらしさ」のデータベースを構築することを「clean学習」と呼んでいます。
当プラグインではメールヘッダに判定結果や判定理由を書き加えるようになっています。
| メール受信時判定結果 | |
| X-BkASPil-Result: none | 通常時 |
| X-BkASPil-Result: spam | spam判定時 |
| X-BkASPil-Result: white | IPアドレス、メアドなどがホワイトリストにあった場合 |
| 判定理由追加ヘッダー | |
| X-BkASPil-Comment: MISHOUDAKU | 未承諾広告判定時 |
| X-BkASPil-BLIP: IPアドレス | ブラックリスト参照方式によるspam判定 |
| X-BkASPil-BayesResult:1以下の数字 | ベイジアンヒット時の計算値 |
| その他 | |
| X-BkASPil-Learn: spam | ベイジアンフィルタのspam学習実施済 |
| X-BkASPil-Learn: clean | ベイジアンフィルタのclean学習実施済 |
| X-BkASPil-Comment: MANUAL | 判定の訂正後 |
| X-BkASPil-TLD: | TDL拒否時に付記 |
当サイトがベイジアンフィルタを導入するに当たっては以下のサイトなどにお世話になりました。